
Comunicación Greencities&Sostenibilidad 2013/Bienal/ Edificación
El uso eficiente de los recursos es un reto universal de la sociedad actual y así lo refleja la Comisión Europea en su Hoja de Ruta. En la última década, han tenido lugar grandes avances en este campo que han potenciado los conceptos de Red Inteligente y Ciudad Inteligente.
La generalización del uso de medidores inteligentes y sensores de distinto tipo en el ámbito doméstico, permite extraer de forma fácil y asequible datos de consumo, luminosidad, etc. Se parte de la idea de aprender de dichos datos para extraer valor de los mismos. El conocimiento de los hábitos de consumo del usuario y de su entorno permitirá llevar a cabo acciones que ayudarán a mejorar la eficiencia energética.
Se pretende mostrar en esta comunicación un compendio de cuáles pueden ser esas técnicas de aprendizaje automático, así como un estudio comparativo de las alternativas que la tecnología ofrece para poder llevarlas a cabo. Teniendo en cuenta que toda solución planteada ha de ser escalable, ya que los datos utilizados se generan de forma creciente a lo largo del tiempo, y el número de hogares que integran este tipo de dispositivos va en aumento, el uso de técnicas Big Data será crucial.
1. Introducción
Durante más de dos décadas la Unión Europea (UE) ha basado su política de mejora de la eficiencia energética en estrategias orientadas a la reducción del consumo de energía y la prevención del derroche energético. De esta forma, la UE intenta contribuir de forma decisiva a la competitividad, a la seguridad del abastecimiento y al respeto de los compromisos asumidos en el ámbito del Protocolo de Kioto sobre el cambio climático (Grubb et al., 1999). Entre las numerosas fuentes potenciales de reducción de consumo energético se encuentran las viviendas, en las que la Comisión ha centrado sus esfuerzos que se resumen en la Directiva 2010/31/EU denominada Energy performance in buildings (Commission, 2010), donde se remarca que dentro de este ámbito se consume el 40% de la energía final de la UE. Por otro lado, el 20 de junio de 2013, se publicó el estudio titulado “Certificados de eficiencia energética en edificios y su impacto en la transición de precios y alquileres en países de la Unión Europea” cuyas conclusiones manifiestan que las iniciativas de certificación energética obligatoria como el R.D. 235/2013 (Ballesteros and Shaw, 2013) tendrán un efecto positivo en el mercado de viviendas, donde se valorizarán aquellas con mejores índices de eficiencia.
Sin embargo, en general todas estas iniciativas no han tenido la repercusión esperada a corto plazo y el usuario no elige una vivienda u otra por su certificación energética, o el criterio más relevante cuando se presenta la ocasión de cambiar de electrodoméstico no suele ser su nivel de eficiencia, sino otros como su precio o sus prestaciones. Y aunque efectivamente, la concienciación sobre el cambio climático, la necesidad de consumir menos y de forma eficiente estén cada vez más presentes en nuestra vida diaria, el usuario final espera que su hogar y los elementos que lo integran le aporten una mejor calidad de vida y no que suponga una preocupación adicional que en muchos casos no comprende o no le interesa.
Aquí es donde proyectos como Smart Home Energy (SHE) (SHE Consortium, 2012) se presentan como auténticos asistentes energéticos que permiten que el usuario final gestione su vivienda de forma integral y desatendida para garantizar los criterios de eficiencia energética y alcanzar en todo momento el punto mínimo de demanda y consumo. Para conseguir este objetivo, este tipo de sistemas descansan sobre tres pilares fundamentales: monitorización, predicción mediante aprendizaje automático y control. De esta forma, proyectos como el presentado en esta comunicación, son capaces de caracterizar el comportamiento energético de una vivienda y emitir las recomendaciones o correcciones oportunas para su autogestión.
El documento se organiza de la siguiente manera: primero se hará un estudio de las investigaciones relacionadas tanto por mejorar la eficiencia energética, como por aplicar técnicas similares en otros campos. Posteriormente se hace un repaso de las alternativas tecnológicas que dan soporte al sistema propuesto, que a continuación es descrito en la sección 4, describiendo sus principales módulos. Finalmente se presentarán las conclusiones y el trabajo futuro en la última sección.
2. Estado del Arte
La base de todo modelo de autoaprendizaje se caracteriza por su capacidad de predecir el comportamiento de un sistema para elaborar estrategias de control para un fin concreto. El uso de técnicas de aprendizaje automático ha sido aplicado con éxito a otros campos.
En concreto, los sistemas recomendadores basados en las preferencias y similitudes de los usuarios están cada vez más presentes en los entornos y aplicaciones de uso diario. Uno de los casos más conocidos, es la web de compras Amazon, donde los usuarios reciben recomendaciones basadas en las compras realizadas por usuarios considerados similares (Linden et al., 2003). De igual forma, el popular servicio de vídeo bajo demanda Netflix usa las puntuaciones que los usuarios dan a las películas que ven, para proponer películas que a otros usuarios con gustos similares (Xavier Amatriain, Justin Basilico, 2012). También es muy habitual el uso de estos sistemas en servicios de búsqueda de pareja para proponer posibles candidatos a los usuarios del servicio.
En cuanto a predicción, conocidos son los casos de aplicación de este tipo de técnicas en la economía, para tratar de conocer la futura evolución de los mercados (Satchell and Knight, 2011), en la medicina, donde este tipo de técnicas pueden ayudar por ejemplo a anticiparse a un posible derrame cerebral (Khosla et al., 2010), etc. También es posible realizar tareas de clasificación e identificación, como demuestran diversos estudios en el campo de la visión por computador (Chechik et al., 2010) y la detección de elementos maliciosos en la web (Ma et al., 2009).
Retomando el tema de esta comunicación, hay que tener en cuenta que una vivienda es un modelo complejo que integra diferentes elementos de consumo (electrodomésticos y vehículos eléctricos), fuentes de incertidumbre (temperatura exterior y comportamiento de sus ocupantes) y fuentes de producción energética (equipos de aire acondicionado, calderas, placas solares o fotovoltaicas, otras energías renovables, etc.). Para diseñar y desarrollar un sistema de gestión energética para hogares, resulta imprescindible que el mismo sea capaz de predecir parámetros como la temperatura o la demanda de energía. Estudios previos demuestran que modelos predictivos basados en redes neuronales (González Lanza and Zamarreño Cosme, 2002)(González and Zamarreno, 2005) y Support Vector Machines (SVM) (Zhao and Magoulès, 2012) son capaces de predecir tanto la evolución de la temperatura en un edificio como el consumo de sus equipos, lo que permite elaborar medidas correctivas que ayuden a mejorar la eficiencia energética de los hogares.
3. Tecnologías implicadas
Recolección de datos
La adquisición de datos comprende por una parte el hardware y por la otra el software. Respecto al hardware, es necesaria la instalación de medidores inteligentes en el hogar, que sean capaces de obtener el consumo cada cierto valor de tiempo.
El proyecto SHE pretende ser independiente del hardware, y actualmente incluye soporte para los medidores EcoManager de Current Cost (Current Cost, 2012) y los de Plugwise (Plugwise, 2012), que se pueden ver en la Figura 1. Ambos se basan en una red de dispositivos que se sitúan entre el electrodoméstico y el enchufe y envían datos a otro dispositivo central por medio de radiofrecuencia y ZigBee respectivamente.

Figura 1: Medidores inteligentes de Current Cost (a) y Plugwise (b)
Además se puede recoger otra información del hogar (luminosidad, temperatura, nivel de polución, etc.) por medio de sensores, como los que se muestran en la Figura 2.

Figura 2: Sensores de luminosidad, temperatura y Monóxido de Carbono (CO)
Los datos son extraídos de los medidores y sensores mediante un adaptador software, y ofrecidos como servicio energético a través de la tecnología Web Service for Devices (WS4D) (“Web Services for Devices (WS4D) Website,” 2012). Este servicio será consumido por los elementos encargados de realizar el aprendizaje automático, y que se describen en la sección 4 de este documento.
Almacenamiento y procesamiento de datos
Los datos obtenidos del hogar se almacenan de forma centralizada gracias a la tecnología Cloud (Rhoton and Haukioja, 2011), que permite que no sea necesario tener gran capacidad de almacenamiento en la propia vivienda. Además ofrece facilidades para gestionar y mantener la integridad, seguridad y disponibilidad de los datos, almacenando réplicas de los datos para ser usadas en caso de pérdida de información.
Otra tecnología clave en el sistema ya que permite su escalabilidad es Big Data (Marz and Warren, 2013). A través de una inversión en tecnología lineal en costes, permite cubrir las necesidades de almacenamiento y procesamiento, así como una gestión elástica de la infraestructura de Tecnologías de Información (TI), adaptándose en tamaño según las necesidades. Big Data da soporte a gran volumen de datos de diversos tipos, procesándolos en un tiempo admisible. Además ofrece soporte para algoritmos de aprendizaje automático, herramientas de minería de datos visuales, monitorización próxima a tiempo real, y una serie de nuevas posibilidades de análisis y procesamiento de la información que encajan perfectamente con el sistema propuesto.
La frecuencia estandarizada en medición de energía es de una medición cada 15 minutos, debido a las limitaciones existentes con las tecnologías precedentes a Big Data. Aumentar la frecuencia de las mediciones permite tener un conocimiento más detallado de lo que ocurre en el hogar y realizar así actividades diferentes con la información. Disminuir a una frecuencia de una medición cada segundo, por ejemplo, supone un incremento enorme de la capacidad necesaria para almacenar y procesar la información. Igualmente, monitorizar varios dispositivos en un mismo hogar, o desglosar el consumo general en varios dispositivos, supone a su vez un importante incremento. Además, la incorporación de la práctica totalidad de consumidores a estas técnicas de medición supondría un importante incremento de los requisitos de comunicaciones, almacenamiento y procesamiento.
Un hogar bajo estos requisitos de medición, provocaría la transmisión y el almacenamiento de 1 kb por segundo. Esto implica la necesidad de un sistema capaz de recibir y almacenar 32 Petabytes por Millón de usuarios al Año (PMA). Adicionalmente, será necesario dar soporte al almacenamiento y procesamiento de las operaciones a realizar con toda esta información, que según las funcionalidades que se pretendan ofrecer podría elevar enormemente esta cifra.
Entre los requisitos que se pretenden, están el que un usuario pueda acceder de forma remota al sistema con asiduidad (dependiendo del tipo de usuario desde varias veces al día, a una vez al mes) y consultar el detalle de consumo. Además el sistema, a partir de esos datos de consumo, debe poder emitir de forma personalizada para cada usuario, recomendaciones energéticas, alertas sobre malas prácticas y predicciones de consumo con la mayor certeza posible (toda toma de decisión se acaba basando en una predicción), etc.
Herramientas de aprendizaje automático
A la hora de realizar un aprendizaje automático, el uso de una herramienta adecuada puede simplificar considerablemente la labor. En este caso, las alternativas estudiadas se muestran en la Figura 3. Primeramente, Weka (Frank et al., 2010) se trata de una herramienta muy consolidada que tiene la principal ventaja de incorporar un gran número de algoritmos de aprendizaje, por lo que puede ser un software muy útil en fases previas de estudio, para probar los algoritmos, y analizar los datos y posibles tendencias o relaciones entre ellos. Su gran desventaja es que no ofrece soporte para Big Data con lo que se han estudiado otras alternativas más específicas para la cantidad y variedad de datos que se van a manejar en el sistema propuesto. Entre ellas, cabe destacar Mahout (Owen et al., 2011) y Jubatus (Jubatus WebSite, 2011).
Mahout es un proyecto Apache Open Source, aun en desarrollo, que ofrece una implementación en Java de diversos algoritmos de aprendizaje automático, tanto de clasificación, como de clustering y recomendación. En su hoja de ruta existe el planteamiento de ir incrementando y diversificando los tipos de algoritmos soportados. Su gran ventaja es la escalabilidad que ofrece al correr sobre Hadoop y su arquitectura MapReduce (Lam, 2010). Esto también le otorga cierta simplicidad para su integración en un sistema Cloud.

Figura 3: Herramientas de aprendizaje automático estudiadas
En cuanto a Jubatus, es un framework que tiene la particularidad de que el aprendizaje que realiza es en línea, es decir, el modelo se va actualizando en cada iteración, por lo que no requiere capacidad de almacenamiento y además permite ofrecer una primera respuesta en un espacio de tiempo menor, aumentando su precisión con el tiempo. Su arquitectura cliente/servidor también es escalable y ofrece clientes para varios lenguajes (Java, Python, C++, Ruby) con un paquete de algoritmos muy novedosos ya implementados. Aunque como se trata de un proyecto reciente, aún quedan muchos algoritmos por incorporar, en especial aquellos que tratan con series temporales de datos, cuyas características intrínsecas les convierten en un caso particular.
4. Sistema propuesto
El sistema propuesto, que se puede ver gráficamente en la Figura 4, hará uso de las tecnologías expuestas en el apartado anterior, para realizar un aprendizaje automático que ayude a mejorar la eficiencia energética del hogar a través de recomendaciones colaborativas, predicciones y análisis de datos. Estas funcionalidades serán descritas en detalle a continuación.
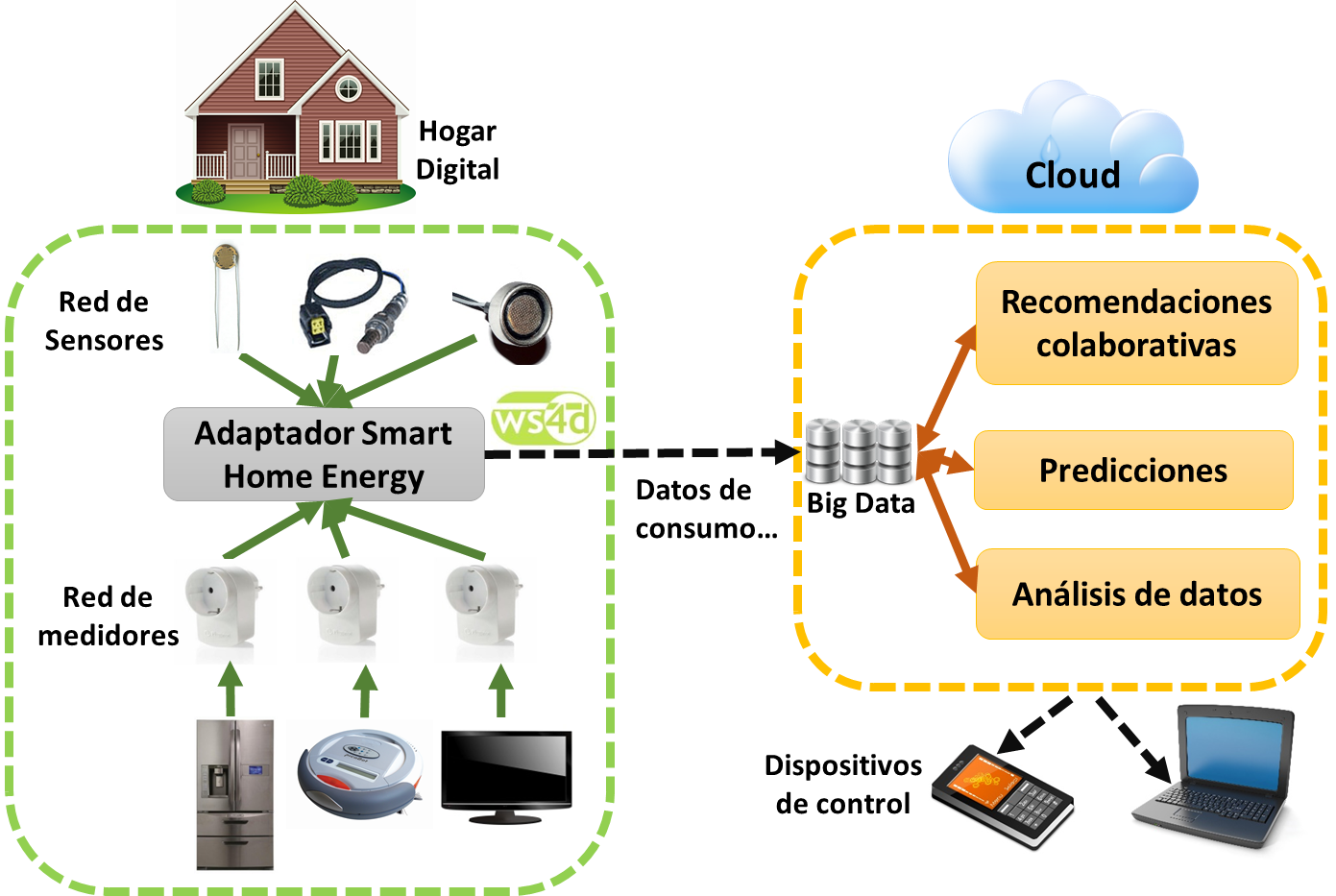
Figura 4: Esquema del sistema propuesto
Recomendaciones colaborativas
La función de este módulo es la de sugerir a los usuarios la realización de acciones que otros usuarios similares han realizado en sus viviendas y que les han ayudado a reducir el consumo energético.
Para ello será necesario definir la forma de calcular la similitud entre dos usuarios, o lo que es lo mismo, la “distancia” entre ellos. Para calcular esta distancia existen diversos algoritmos, como el coeficiente de correlación de Pearson, la distancia euclídea, el coseno, etc. Estos algoritmos se basan en que los usuarios valoran las acciones que toman dentro de un rango de valores, lo que indica su grado de aceptación.
En el sistema concreto que se propone en este trabajo, los usuarios no dan una valoración de cuánto están de acuerdo con la realización de una acción, sino que se van a limitar a decir si están de acuerdo o no. Es decir, un usuario o bien no acepta la acción (valor 0) o la acepta completamente (valor 1). Para este tipo de valoración los algoritmos más adecuados son los de Tanimoto (Cechinel et al., 2013), disponibles en Mahout. El algoritmo de Tanimoto se basa en el cálculo del coeficiente de similitud de Tanimoto (1), que también se expresa como (2).
| |
(1) |
| |
(2) |
Donde:
- A = número de acciones realizadas del usuario 1
- B = número de acciones realizadas del usuario 2
- C = número de acciones realizadas comunes de los usuarios 1 y 2.
Usando esta fórmula se calculan todas las distancias entre los usuarios y se construye una matriz donde se almacenan todos estos datos. En el momento de realizar una recomendación a un usuario, el algoritmo devuelve aquellas acciones que los usuarios más similares al usuario han realizado, y que el usuario al que queremos ofrecer la recomendación no ha realizado todavía.
Predicciones
Para lograr un uso eficiente de la energía se proporciona un sistema de predicción, que llegue a aprender las pautas de consumo de un determinado domicilio. Este conocimiento recoge el comportamiento por aspectos técnicos y por los hábitos de vida, de manera que un usuario puede predecir su consumo y adaptar sus actividades a unos hábitos de consumo energético más eficientes económicamente (trasladando las acciones a momentos con mejor tarifa) y más responsables ambientalmente.
El sistema genera varias veces al día, a partir de cantidades masivas de información, una predicción semanal de consumo para cada usuario, como la que se puede ver en la Figura 5. Para realizar este tipo de predicción, se tienen en cuenta factores de consumo propios del usuario, factores de consumo generales, y otros factores externos que son relevantes, como por ejemplo horarios, calendarios de festivos, precios, tarifas, meteorología…
La estrategia aplicada por el modelo, permite definir y ajustar la forma en que el sistema aprende, qué datos son relevantes, qué datos no lo son, y qué datos se deben filtrar o potenciar en el aprendizaje. El uso de un algoritmo de aprendizaje proporciona un mecanismo de memorización, capaz de recordar y olvidar en proporciones adecuadas las situaciones vividas, y de proporcionar un valor coherente para situaciones no ocurridas anteriormente.
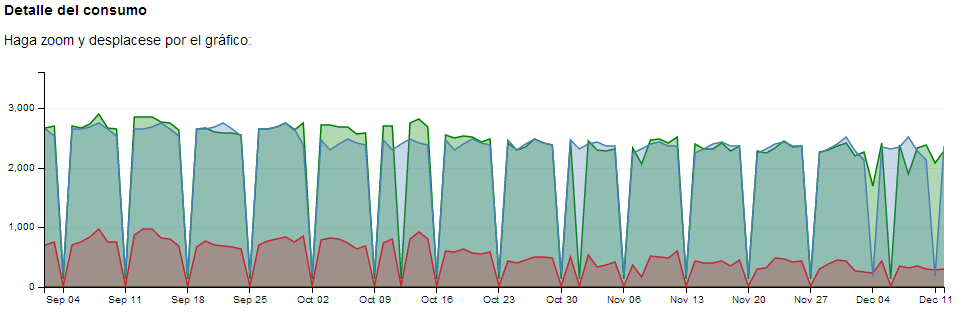
Figura 5: Gráfica de predicción generada por el sistema, comparada con la medición real. En azul la predicción de consumo, en verde la medición de consumo, en rojo el consumo de climatización.
El modelo ha sido probado y entrenado con edificios ubicados en varias zonas climáticas y se ha obtenido un resultado satisfactorio en todos los casos. La eficacia del sistema de predicción se ha evaluado mediante el análisis de estadísticos. La interpretación de estos estadísticos permite evaluar el error cometido en la predicción y la forma en que este error se distribuye. La idoneidad de la técnica es dependiente de la interpretación de estos estadísticos frente a las situaciones a detectar o evitar.
Las pruebas realizadas, cuyo resultado se muestra en la Tabla 1, aportan un resultado de aplicación del modelo sobre datos reales de un establecimiento comercial que presentan los siguientes valores de estos estadísticos:
Tabla 1: Resultados de la evaluación de la eficacia del sistsistema de predicción por medio de estadísticos
| Estadístico | Zona Climática | Interpretación |
| Media del error absoluto (MAD)Donde es el error del pronóstico del período t | Atlántica=237.46Continental=207.59 | Media de errores de predicción cometidos. Da una perspectiva del error que puede cometerse en una predicción.El valor es similar en ambas zonas climáticas y presenta un mejor ajuste en clima continental. |
| Media del error absoluto porcentual (MAPE) | Atlántica=0.099Continental=0.194 | Indica la probabilidad [0,1] de la media de los errores de predicción cometidos. La técnica presenta un mejor valor en el conjunto de datos de clima oceánico. |
| Porcentaje de acierto del error absoluto porcentual (PA)PA = 1 – MAPE * 100 | Atlántica=90.09%Continental=80.59% | Presenta el valor MAPE en forma de acierto porcentual [0,100] %, lo que permite comparar el algoritmo en diferentes conjuntos de datos con valores diferentes. La técnica muestra un mejor valor en el conjunto de datos de clima oceánico. |
| Indicador del error total medio producido en las predicciones R M S D Valores de la predicción en el tiempo |
Atlántica=333.03Continental=281.17
Los errores se encuentran muy repartidos a lo largo del tiempo si el valor es bajo, o muy concentrados en determinados momentos si el valor es alto. Tener errores concentrados puede interpretarse como más conveniente por poder ajustarse como anomalías o poder asociarse nuevas variables no contempladas.La técnica muestra mayor concentración de error en el caso de clima oceánico que en continental.Desviación estándar (DS)Atlántica=233.49Continental=189.63Indica la dispersión del error respecto de la media de error, es decir, si el error está concentrado en algunos puntos o repartido uniformemente. En el primer caso, el algoritmo tendría un comportamiento estable en cuanto al error que comete en cada predicción, mientras que en el segundo, existirían grandes variaciones entre diferentes predicciones.La técnica muestra un mejor valor en el caso de clima continental que en el oceánico.
Para que la información de la predicción sea interpretable para el usuario y éste pueda tomar decisiones, se presenta en forma de gráfica de consumo diaria. Esta gráfica puede realizarse por tramos diarios y ponderarla según la tarifa aplicable en cada tramo, de forma que el usuario pueda acomodar las actividades en el mismo día bajo diferentes tarifas.
Análisis de datos
Las técnicas conocidas como Insight y Visual Mining permiten al usuario disponer de una herramienta generalizada que puede ser personalizada en el momento del uso para obtener sus propias conclusiones sobre sus datos y tomar así sus decisiones.
Mediante dichas técnicas se presenta la información del hogar al usuario de una forma visual altamente expresivas, permitiendo que de un vistazo, se pueda asimilar mucha información variada, evitando así tener muchas gráficas de elementos disjuntos.
Una gráfica relevante es el “Heat Map” de consumo. Como se puede ver en la Figura 6 el consumo es representado en un disco compuesto por siete circunferencias concéntricas (una para cada día de la semana) y 24 segmentos (uno para cada intervalo horario), donde el color corresponde a la intensidad de consumo. Esta gráfica facilita al usuario detectar diferencias de consumo entre días de la semana, y por tanto asociarlo a hábitos para mejorarlos. Además, permite al usuario navegar por diferentes semanas y seleccionar que dispositivos quiere analizar.
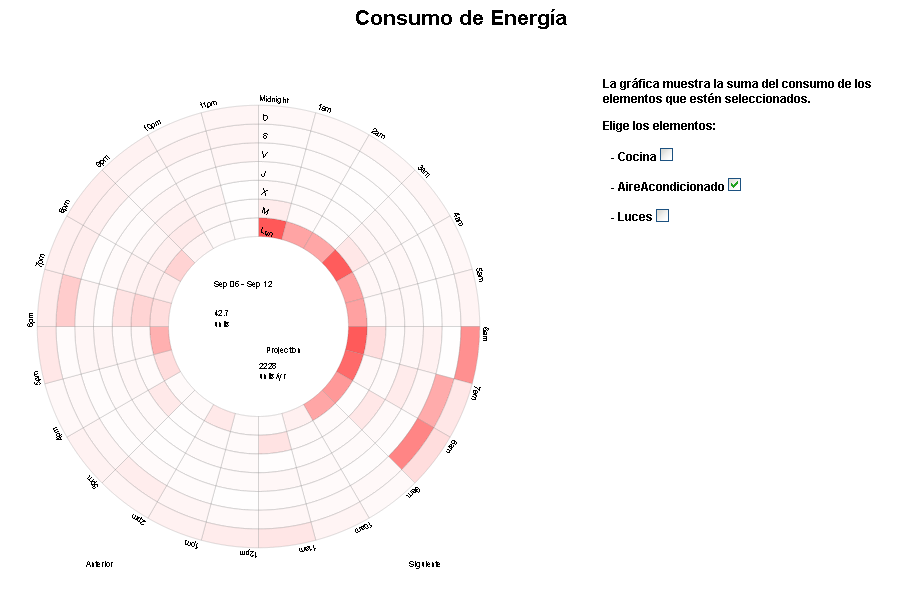
Figura 6: Prototipo del interfaz gráfico Heat Map de consumo mostrando el consumo de aire acondicionado.
Además, se dota a la aplicación de capacidad de inspección, permitiendo al usuario seleccionar tramos, y filtrar así el resto de información de cara a facilitar la obtención de conclusiones. De esta forma, un usuario puede por ejemplo seleccionar su consumo los lunes, entre cierto intervalo horario. El usuario, al seleccionar, puede ajustar las gráficas al intervalo seleccionado, realizando zoom sobre ese intervalo y filtrando los datos. Además, puede navegar por las gráficas desplazándose por el eje de coordenadas que representa el tiempo. En la Figura 7 se muestra un prototipo de la interfaz gráfica propuesta.
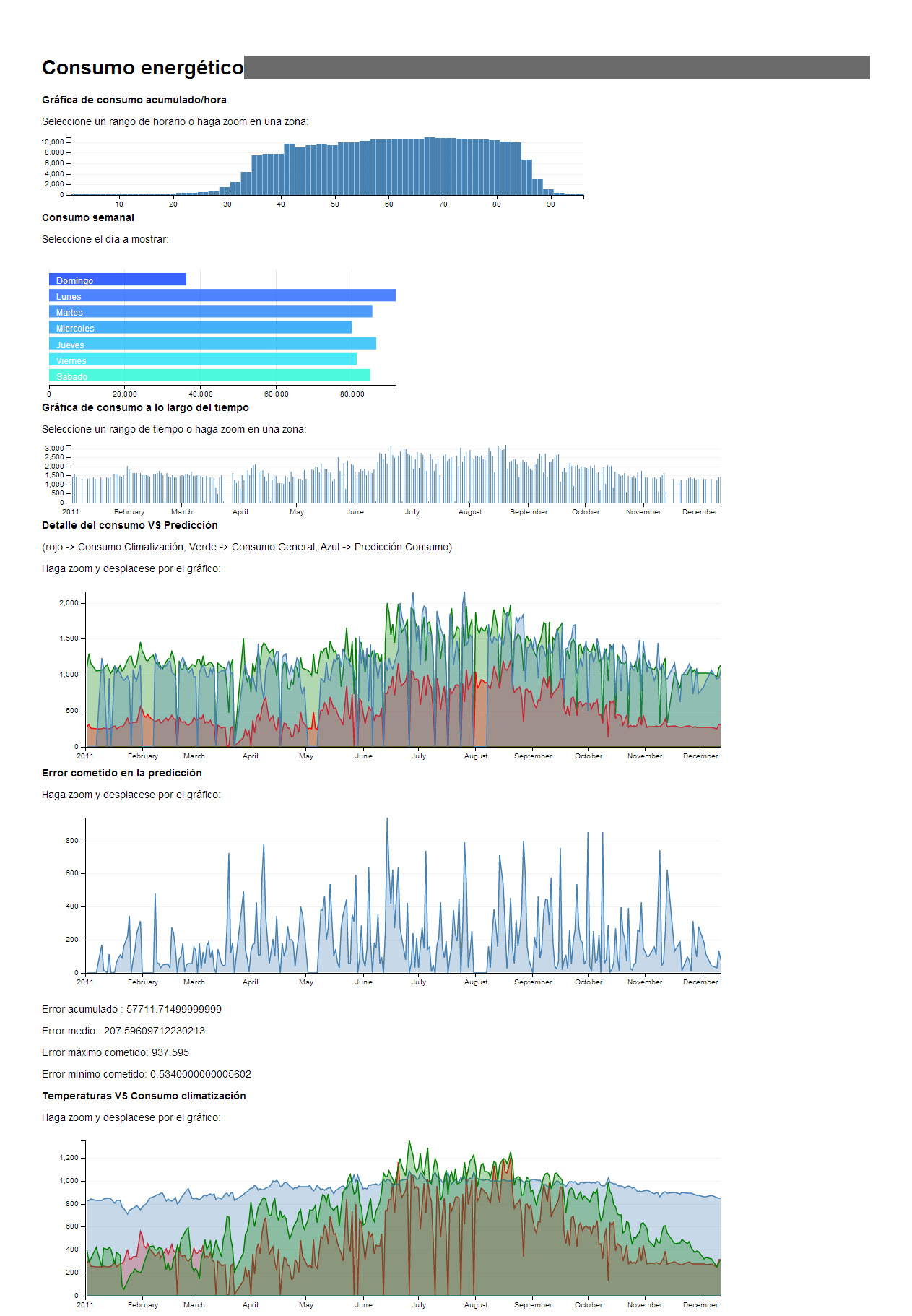
Figura 7: Prototipo del interfaz gráfico Insight de consumo
5. Conclusiones y trabajo futuro
El conocimiento energético del hogar es un factor clave para lograr un uso eficiente de los recursos. El uso extendido de medidores y sensores a nivel residencial, facilita la obtención de la información del mismo, pero esta información, debido a su variedad y tamaño, no es asumible para ser procesada de forma manual, por lo que es necesario recurrir al uso de técnicas de aprendizaje automático.
Dentro del contexto de la eficiencia energética en el hogar, un recomendador colaborativo permitirá sugerir acciones que permitan ahorrar energía a grupos de usuarios de perfil similar sin necesidad de tener un conocimiento previo de esos usuarios y de sus características.
La posibilidad de realizar predicciones de coste de consumo con tarifa energética para la planificación diaria en tarifas discriminadas, permitiría a un usuario realizar una mejor distribución en el día de sus hábitos de consumo.
Además de las recomendaciones y las predicciones, se le ofrece al usuario una herramienta para realizar análisis manuales él mismo, que de otra forma serían inabarcables, dada la cantidad ingente de datos que pueden llegar a surgir de un hogar digital.
Otro campo prometedor es la anticipación a la demanda energética. En el sistema propuesto, a través de predicciones se podría permitir que los comercializadores y empresas de servicios energéticos pudieran realizar una compra más inteligente de energía y un análisis de acciones de eficiencia para sus clientes.
Una posible línea futura sería la de identificar los dispositivos a partir de sus datos de consumo cuando éstos se conecten a la red, permitiendo así anticiparse a la demanda. Para ello, se plantea la posibilidad de entrenar un clasificador de forma supervisada, es decir, mediante datos de consumo etiquetados con el identificador del dispositivo que los generó. En una segunda fase en clasificador ha de ser testeado, y ajustado hasta alcanzar una precisión óptima. Otro posible paso en la mejora de la eficiencia energética es la de dotar al sistema con la capacidad de simular acciones, para estudiar el impacto que tienen las mismas tanto económico como en el consumo.
Autores:
Dr. Ignacio González Alonso (Universidad de Oviedo); María Rodríguez Fernández (Universidad de Oviedo); Juan Jacobo Peralta (Instituto Andaluz de Tecnología); Adolfo Cortés García (Ingeniería de Integración Avanzadas (Ingenia), S.A.); y José María Ocón Quintana (SATEC, Sistemas Avanzados de Tecnología, S.A.)